


Karl Hribernik
UPTIME Project Coordinator
BIBA - Bremer Institut für Produktion und Logistik GmbH
UPTIME Project Coordinator
BIBA - Bremer Institut für Produktion und Logistik GmbH

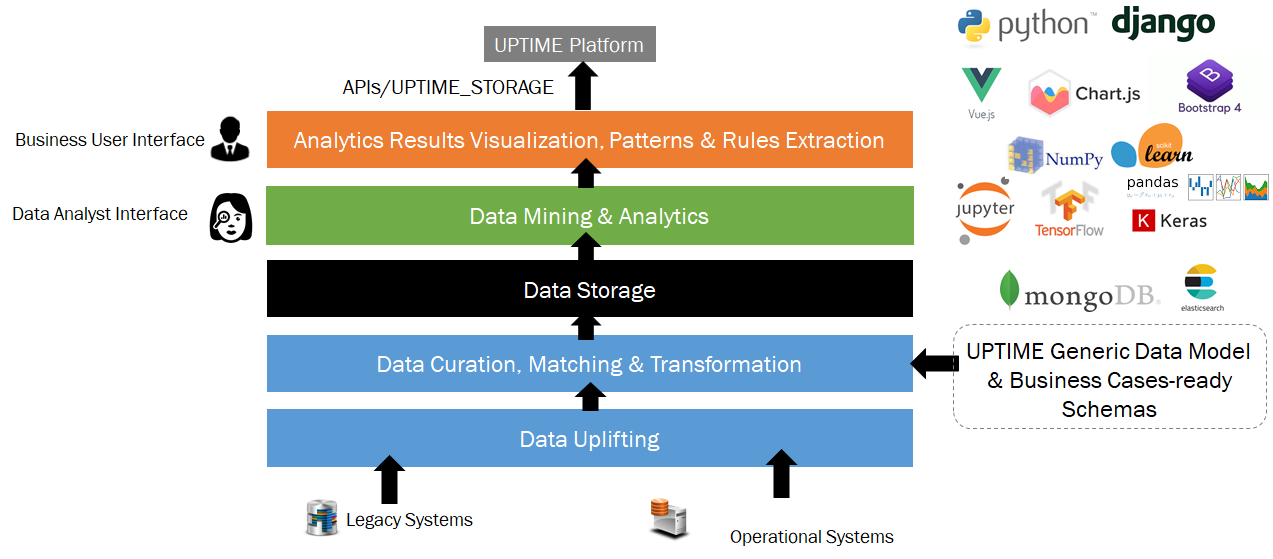
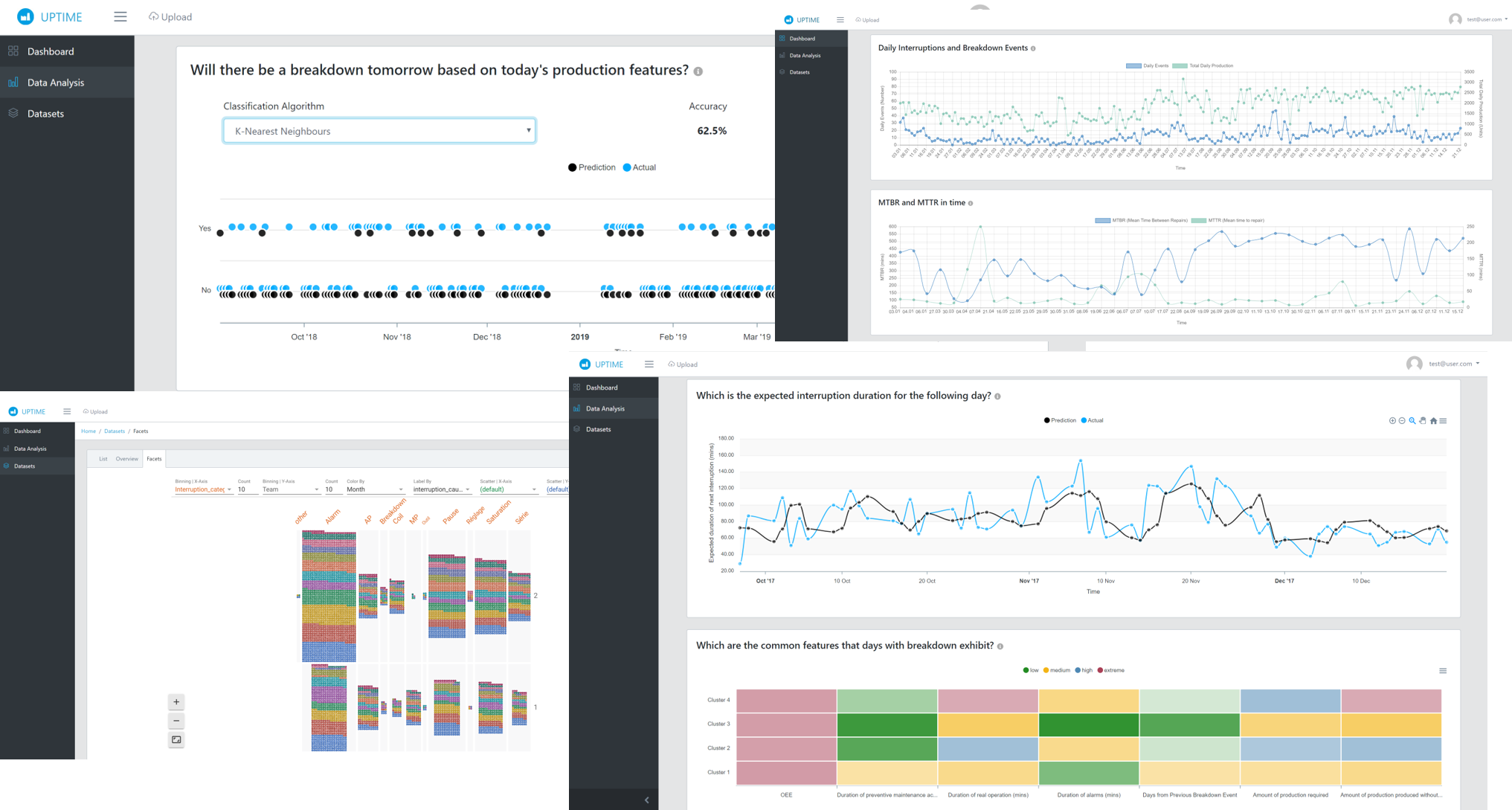

Dr. Fenareti Lampathaki Technical Director
Suite5
Data Intelligence Solutions Limited
Suite5
Data Intelligence Solutions Limited
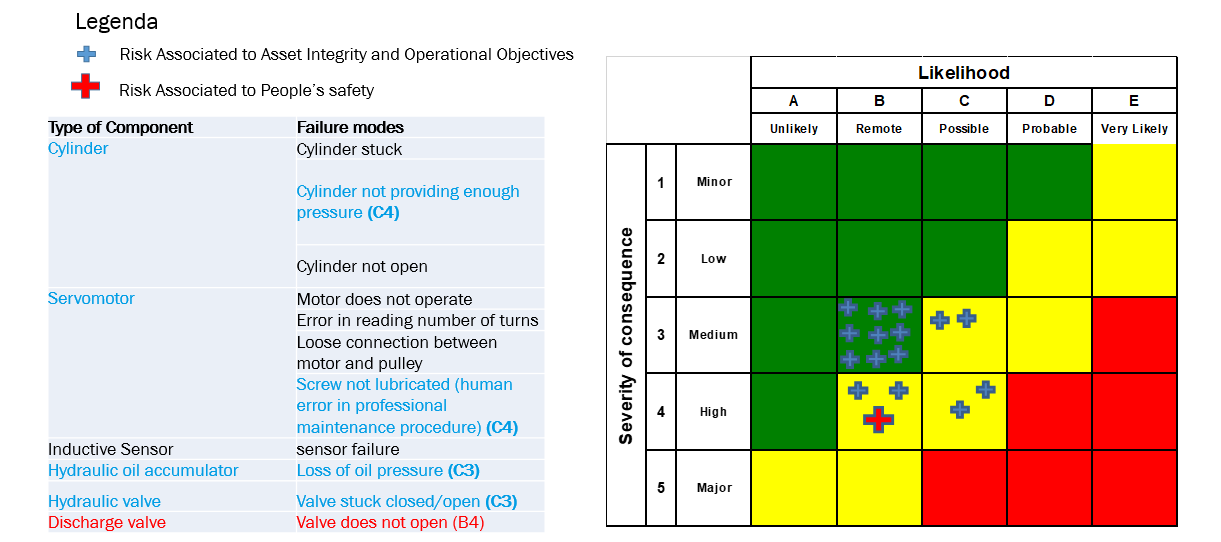

Manuele Barbieri Corporate R&D Project Technical Coordination RINA Consulting S.p.A.

Pierluigi Petrali
Head of Manufacturing R&D
Whirlpool Corporation
Head of Manufacturing R&D
Whirlpool Corporation

0



